

现在的办公室工作环境,协同办公软件是必不可少的工具,企业微信,飞书,Teams,Zoom都是这一类的软件;这类app的最核心的部分是两个,message sync和meeting call, 每个软件都有各自的特色,本文想结合自己的工作经验,稍微详细地讨论一下message sync部分的主要原理和目前的最新的技术
首先,web应用目前是在某一种大一统的方向上,得益于react之类的框架以及软件打包功能的完善,一套js/ts代码全吃desktop和web端的优势越发明显,维护和发布的工作量减轻是所有大型软件的开发团队都乐于见到的
但是目前web api也有非常多的局限性,比如cache storage管理部分;浏览器虽然支持indexed db的读写操作,但是对于复杂且大量的数据,app自身在大多数情况下还是不得不自己处理memory/db的cache读取工作,而且对于复杂schema的数据,还不得不自己定义class/interface以及implementation以便能够处理需要应对的场景
本人所在的组最近就因为选用的library的局限性,在新功能的拓展中吃尽苦头;为了利用到memory读取的速度优势,不得不写复杂的代码去维持memory和db中数据的一致性,特别是如果数据的读取是任意的情况下,这个一致性的维护就特别头疼,比方说下面的例子
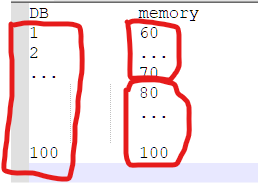
DB中有全部的数据1 to 100, 但是因为分段读取的场景,memory中只有80 to 100, 以及 60 to 70 两段数据
这个情况下,当要提取60 to 100 的所有数据的时候memory中的数据就不完整,而且数据的完整性也无法得到validation,除非我们再一次scan所有db的数据,但是这样就丧失了memory的速度优势
主要问题就是,因为数据读取场景的随机性,使得数据的一致性维护变得复杂,特别是要维护memory和db两个副本,而且要处理network sync的时候 (这里就不展开network sync部分了)
这里的解决方案有两种:
- 像wechat那样,直接放弃network sync,所有的message数据都在本地,这样省掉了network sync的部分, 本地可以根据使用场景做一致性验证 (比如总是从最新的message开始读,每次翻页都记录一个db to memory的cursor)
- 完全放弃memory,只保留一个indexed db副本;其实这个数据一致性问题的关键在于”从db读取数据写入memory的时候,保证memory数据的准确性,以便读取的时候memory的数据是正确的”,比如上面60 to 100的例子,memory、db自身的数据都是valid的,但是如果比较二者,在60 to 100的读取场景下,memory的数据就不完整了;如果只有db一个副本,就没有这个烦恼了, 但是相对的,app就得付出没有memory缓存的代价,performance
cache storage这部分的内容先到此为止,有时间再写更详细的内容,其实最近我们在测试时候发现,memory相比indexed db,如果读取数据量不是非常大,perf的区别其实没有想象中那么大,~100ms,但是这个需要更多测试数据来验证,我目前无法下结论
第二部分,也是最核心的部分,消息同步
其实,严格意义上来说这个分为两部分,real-time update(实时收发)和sync(同步),但是sync这个词太过模糊,即便是程序员群体里也有大部分人不懂sync到底是什么
real-time update就是人与人在相互发消息聊天的时候,message怎么能低延迟地发送到双方的client里
sync,同步,我们工作中的定义其实是指,客户端重启的时候,本地没有最新的message,需要通过GET的API call去从服务器fetch在app不启动的那段时间内,没有实时接收到的数据 (sync 这个词,我个人理解,应该更多的是指进行了GET/POST的API request,例如笔记内容POST到服务器存储,outlook打开GET接收最新的内容,完全不应该涉及real-time update实时更新的这部分内容,因为实现的原理是完全不一样的)
real-time update 部分,如果用户量不大,可以考虑longpoll, 也就是长轮询,细节略去,本质就是不停地做GET call,来持续丰田车最新的数据;但是这种方式在费用,以及推送实时通知方面有本质的缺陷,所以最新的替代方式都是用web socket去保持一个服务器端持续push推送的connection
sync部分,其实本质就是后台message service的搭建,以及各种API的设计;对于从零开始的小公司,可能负担比较小,但是大公司现在推行微服务的想法下,很容易出现这种情况,A组弄了个非常generic的message service,B组最开始用A的service,但是后来发现无法满足需求了,让A组xxx死线之前改,但是A组处于planning以及兼容性的问题,无法或者不能够提供需要的支持,不得已B组自己弄了个新的service,而且不得已对于已经在A里面的数据做了缓存(或者second copy),然后以后遇到问题,无尽地扯皮就开始了
其实问题就在于组织架构一旦大了,架构在设想很多问题的时候无法做到面面俱到,特别是某个产品想要快速上线的时候,不得不借用已经现成的service,这就对于后面的新功能添加设置了隐形的code debt。大家都想有时间去清理debt(aka 屎山),但是谁都没时间,这种东西积累到一定程度就不得不重构,也就是所谓的v2/v3新版本发布的时候。到现在虽然我已经明白了,这可能是软件工程现在这个体系下,不得不重复发生的时候,但是作为一个有点代码洁癖的程序员,这种现象的存在还是觉得很可悲。。。
OK,讲了很多,其实本来想聊更具体一点的技术细节,但是时间精力不允许,今年的帖子就到此为止吧。稍微总结一下:
- web开发大一统的趋势短期内应该都不会改变,但是web API对于某些具体问题的支持还是欠缺,特别是memory/db管理方面
- message sync问题的本质就是处理好两部分问题,real-time update和sync API的支持
- 公司各个部门的微服务架构,其实某方面给产品增加了code debt,积累到一定程度就不得不进行大重置
Leave a Reply to 菜鸟Leek Cancel reply